|
||
Sommario Internet ID Indici di BETA Redazione Mailing list Installazione Mirror ufficiali Licenza Pubbl. Beta Cerca Stampa
|
Reference counted classesdi Michele CrudeleCollaboratore, BETA2 A differenza dei linguaggi procedurali, nei quali esiste un disaccoppiamento tra le strutture dati e le funzioni che le manipolano, nel paradigma object oriented dati e funzioni sono incapsulati in oggetti il cui ciclo di vita è legato all'invocazione di costruttori e distruttori, questi ultimi automaticamente eseguiti quando l'oggetto esce dal suo campo di visibilità. Poiché il programmatore conosce cosa succede ad un oggetto al momento della costruzione e della distruzione, egli può introdurre delle ottimizzazioni per migliorare velocità di esecuzione ed utilizzo della memoria della classe che sta progettando. In questo articolo vogliamo appunto illustrare una tecnica di programmazione che agisce sulla creazione, copia e distruzione degli oggetti, facendo risparmiare memoria e migliorando la velocità di esecuzione: il reference counting. Vedremo come, con un piccolo sforzo aggiuntivo, è possibile progettare una classe String (ancora lei ?) reference counted. Vedremo come rendere reference counted una classe, analizzeremo la natura dei benefici apportati, la tipologia di classi che ne traggono effettivamente vantaggio, ed infine vedremo come si comporta il reference counting nei programmi multithread ed in presenza di riferimenti circolari.IntroduzionePrendiamo le mosse dall'interfaccia di String del Listato 1 e sviluppiamo alcune considerazioni sull'operatore di concatenazione
Listato 1:
class String {
public:
String (const char* cstr = 0);
String (const String& s);
void operator = (const String& s);
~String ();
int length () const;
const char* const c_str () const;
String& operator += (const String& s);
String operator + (const String& s) const {
return String (*this) += s;
};
};
Chiediamoci cosa succede quando concateniamo due stringhe:
String a, b;
String sum = a + b;
String String::operator + (const String& s) const {
String ret;
// calcola this + s
return ret;
}
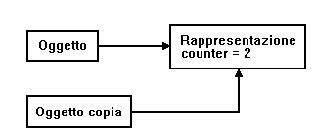
Viene invocato il costruttore di copia di String per assegnare il valore di ritorno a sum, ed il distruttore dell'oggetto ret quando questo esce dal suo campo di visibilità. Quindi la rappresentazione in memoria di ret viene prima duplicata e poi distrutta, operazione che non sembra dotata di molta astuzia. Chiediamoci se possiamo aggiungere un po' di intelligenza per migliorare il passaggio di parametri per valore. Infatti è questo il problema più generale da affrontare; in ogni passaggio di parametri per valore avviene una copia ed una distruzione di quello che è stato copiato. Se in alcuni casi il passaggio per valore è evitabile, in altri come l'esempio appena visto no. Non solo, ma quando è evitabile in alcuni casi lo è a scapito di una qualche caduta di stile. Per esempio: String MiaClasse::evaluate (); potrebbe essere trasformato in: void MiaClasse::evaluate (String&); per evitare il passaggio della stringa di ritorno per valore, ma la prima dichiarazione è certamente più intuitiva e naturale della seconda. In quest'ultima appare evidente l'attenzione posta dal programmatore all'efficienza del codice; ma non tutti siamo sempre così attenti. Cosa possiamo fare dunque per ridurre l'overhead delle invocazioni a costruttori di copia, operatori di assegnamento, e distruttori ? Un oggetto copiato possiede la stessa rappresentazione in memoria dell'oggetto sorgente (anche se questo non è sempre vero); allora perché non copiare soltanto il riferimento allo stato dell'oggetto ? E' ovviamente meno oneroso sia in termini di efficienza (bisogna copiare un puntatore anziché rigenerare l'intero stato dell'oggetto), sia in termini di utilizzo della memoria. In questo modo però abbiamo due entità che fanno appunto riferimento alla stessa memoria (Figura 1).
In qualche modo dobbiamo ricordarcelo, non fosse altro perché non possiamo cancellare tale memoria finché ci sono degli oggetti che la utilizzano. Aggiungiamo dunque un reference counter alla rappresentazione, il cui compito è appunto quello di mantenerne il numero di riferimenti, ossia il numero di oggetti che la referenziano. Quando il reference counter assume il valore zero, allora la memoria può essere rilasciata. Appare evidente a tal punto che questo pattern di programmazione richiede l'utilizzo di due classi C++:
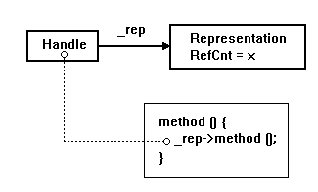
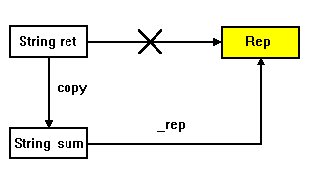
Entreremo fra breve nel merito di queste classi; adesso riesaminiamo cosa accade durante l'invocazione dell'operatore di concatenazione nel nuovo modello di String. La sequenza delle operazioni non cambia, cioè vengono sempre invocati il costruttore di copia ed il distruttore di String, ma adesso ciò che viene copiato è un puntatore (StringRep*), e nulla viene distrutto perché l'oggetto sum referenzia la rappresentazione (ricordiamo che la rappresentazione può essere deallocata soltanto quando non ci sono più oggetti Handle che la utilizzano). L'overhead della copia è stato notevolmente ridotto a quanto pare (Figura 3).
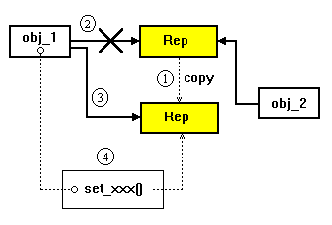
A questo punto vi sarete certamente chiesti cosa succede quando viene invocato un metodo che modifica lo stato interno dell'oggetto. Ebbene, se c'è un solo riferimento attivo, nessun problema, eseguiamo il metodo; ma se ci sono piu' Handle che referenziano la Representation dobbiamo copiare fisicamente l'oggetto e poi modificarne lo stato, altrimenti tutti gli oggetti che referenziano una rappresentazione subiranno una modifica indesiderata (Figura 4).
Vi sarete accorti che la tecnica del reference counting non è altro che una copy on write, cioè un oggetto reference counted viene fisicamente copiato solo quando ne viene modificato lo stato. La classe RepresentationCominciamo ad impostare la Representation per la classe String. Con riferimento al Listato 2, vogliamo implementare una classe String come un array espandibile di caratteri (_cstr) di cui l'attributo _size contiene la lunghezza effettiva e _capacity rappresenta la capacità, ossia il numero di caratteri che può effettivamente contenere. L'array _cstr viene riallocato solo quando gli deve essere assegnata una stringa la cui lunghezza supera la _capacity.
Listato 2:
class StringRep {
private:
int _cnt;
int _size,
_capacity;
char* _cstr;
// ...
};
Oltre a questo, la classe StringRep dovrà contenere un reference counter _cnt che viene totalmente gestito dal suo Handler (String) attraverso le seguenti operazioni:
Proviamo ad incapsulare queste operazioni in una classe che chiameremo con grosso sforzo di fantasia ReferenceCounted (Listato 3):
Listato 3:
class ReferenceCounted {
private:
int _cnt;
void operator = (const ReferenceCounted&);
public:
ReferenceCounted () : _cnt (1) { };
ReferenceCounted (const ReferenceCounted&) : _cnt (1) { };
ReferenceCounted& attach () { ++_cnt, return *this; };
ReferenceCounted& detach () { --_cnt, return *this; };
bool in_use () const { return _cnt > 0; };
bool shared () const { return _cnt > 1; };
};
Una classe Representation è reference counted, quindi perché non derivare StringRep dalla ReferenceCounted ? Guardate cosa ne vien fuori (Listato 4):
Listato 4:
class StringRep : public ReferenceCounted {
private:
int _size,
_capacity;
char* _cstr;
};
La StringRep non ha più traccia del counter (nascosta dall'ereditarietà), ed inoltre abbiamo ottenuto due risultati importanti:
La classe HandleLa classe Handle ha come unico attributo un puntatore (_rep) alla sua Representation. Agisce principalmente da storage manager con l'ausilio del reference counter. Entriamo nel dettaglio della gestione intelligente del reference counter: Tutti i costruttori della classe Handle debbono creare una nuova istanza di Representation con il reference counter inizializzato ad uno
String (const char* cstr = 0) : _rep (new StringRep (cstr)) {}
Poiché StringRep eredita da ReferenceCounted, non c'è bisogno di fare altro perché il contatore viene inizializzato ad uno nel suo costruttore. Il costruttore di copia della classe Handle assegna semplicemente a _rep il corrispondente dell'oggetto copiato e ne incrementa il reference counter invocando il metodo attach() della classe ReferenceCounted
String (const String& s) : _rep (s._rep) {
_rep->attach ();
}
L'operatore di assegnamento è un po' più furbo. Infatti dobbiamo ricordarci di decrementare il contatore del _rep corrente e di cancellarlo se l'oggetto non è più in uso. Fatto questo le operazioni sono le stesse del costruttore di copia
void operator = (const String& s) {
if ( this != &s && rep != s.rep ) {
if ( !_rep->detach ().in_use () )
delete _rep;
(_rep = s._rep)->attach ();
}
}
Analizziamo adesso il distruttore. Dobbiamo decrementare il reference counter dell'oggetto _rep e ricordarci di deallocarlo se non è più usato.
String::~String () {
if ( !_rep->detach ().in_use () )
delete _rep;
}
Cosa facciamo nei metodi che modificano lo stato di un oggetto ? E' semplice e l'abbiamo già accennato precedentemente: se l'oggetto _rep è condiviso (il reference counter è maggiore di uno) ne creiamo uno nuovo per copia; altrimenti possiamo modificarlo liberamente in quanto non apportiamo modifiche indesiderate ad altri oggetti. Un esempio applicativo è l'operatore di concatenamento di String:
String& String::operator += (const String& s) {
if ( _rep->shared () ) {
_rep->detach ();
_rep = new StringRep (*_rep):
}
_rep->insert (s._rep->_cstr);
return *this;
}
Mettiamole insiemeLa classe Handle è usata per accedere un'altra classe dove effettivamente risiede l'intelligenza applicativa: String esegue i suoi compiti accedendo StringRep. Ciò significa che per ogni metodo definito nell'interfaccia di String dobbiamo scriverne uno corrispondente nella classe StringRep ! Ad esempio dovremmo scrivere
int String::length () const {
return _rep->length ();
}
per ottenere la lunghezza di una stringa. Questo se vogliamo tenere completamente separate le due classi Representation ed Handle. Come soluzione non è molto elegante. Ed inoltre, ogni volta che si modifica l'interfaccia di String bisogna modificare anche quella di StringRep.
Ebbene, attraverso questi metodi elementari intuirete che è possibile implementare una interfaccia completa ed abbastanza usabile interamente nella classe String. Praticamente tutto può essere fatto attraverso questi metodi. L'operatore += per esempio è stato implementato in quattro righe utilizzando il costruttore di copia di StringRep ed il metodo di insert(). Quando usare il reference countingIl reference counting può essere usato con successo per quelle classi le cui istanze sono frequentemente copiate attraverso assegnazioni o per passaggio di parametri, in particolare se si tratta di oggetti di grandi dimensioni o tali per cui l'operazione di copia è dispendiosa in termini di efficienza. Attenti a...Il problema principale degli oggetti reference counted è legato all'utilizzo all'interno di programmi multithreading: bisogna serializzarli a livello di infrastruttura, ossia eseguire il codice dei metodi che aggiornano il contatore e lo stato dell'oggetto all'interno di una sezione critica. Ad esempio il metodo attach() dovrebbe essere scritto:
ReferenceCounted& ReferenceCounted::attach () {
EnterCriticalSection (critSec);
++_cnt;
LeaveCriticalSection (critSec);
return *this;
};
E così per tutti gli altri metodi che modificano lo stato di un oggetto StringRep. Qualora ciò non venga fatto, nella migliore delle ipotesi si rischia di perdere il controllo del contatore con conseguenti memory leaks. Lasciamo immaginare cosa altro può succedere se due o più thread di esecuzione accedono simultaneamente lo stesso oggetto.
Michele Crudele è Collaboratore della struttura BETA2 dal 1998; si occupa di sviluppo software object oriented presso IBM-TIVOLI Laboratory di Roma ed è raggiungibile su Internet all'indirizzo mcrudele@tivoli.com. Copyright © 1998 Michele Crudele, tutti i diritti sono riservati. Questo Articolo di BETA, insieme alla Rivista, è distribuibile secondo i termini e le condizioni della Licenza Pubblica Beta, come specificato nel file LPB.
BETA Rivista |
Copertina |
Sommario |
InternetID |
Informazioni |
Browser
|
||||||||||||||||||||||||||||